2022-04-15-java日志中间件
一、日志组件
日志组件,顾名思义就是用来打日志的,下面列一下市面上的名词:
日志组件
JCL JUL SLF4J Logback Log4J Log4J2日志相关的jar包:
log4j、log4j-api、log4j-core
log4j-1.2-api、log4j-jcl、log4j-slf4j-impl、log4j-jul
logback-core、logback-classic、logback-access
commons-logging
slf4j-api、slf4j-log4j12、slf4j-simple、jcl-over-slf4j、slf4j-jdk14、log4j-over-slf4j、slf4j-jcl你可能会想:就简简单单的打个日志,用得着这么复杂么?
刚开始我也是这么想的,后来研究之后发现打日志并不简单。
首先介绍下上面的日志组件。
二、日志的实现与门面
2.1 各种日志工具
JUL
jdk提供的日志工具,全称是java.util.logging,缺点是日志级别分类不清晰,使用成本较高,所以基本没人用。
Log4J
Log4J是由俄罗斯程序员Ceki Gülcü开发的,发展一段时间后,这哥们将这个Log4J捐献给了Apache基金会,Apache借鉴了Log4J的开发思想,孵化出了支持C,C++,C#,Perl,Python,Ruby等语言的子框架。
LogBack
Ceki Gülcü虽然将Log4J捐给了apache后,但发展一段时间后不满Apache对Log4J的管理,决定另起炉灶,重新开发了LogBack这个日志框架(后面的SLF4J是和LogBack一起开发出来的),LogBack相当于对Log4J的优化,就好比mina和netty的关系,性能肯定是有很大提升的,然后LogBack就逐渐的流行开来。牛人就是牛人啊
Log4J2
LogBack流行后,Apache觉得Log4J已经没有继续开发维护的必要了,于是宣布该项目作废,同时借鉴了Log4J和LogBack,开发了Log4J2,号称性能完胜前两者,推荐开发者迁移到Log4J2。
JCL
JCL全称是Jakarta Commons-Logging,Jakarta不是印度首都雅加达,而是早期的Apache的开源项目,用于管理各个Java子项目,比如Tomcat Ant Maven Struts等。2011年12月,在所有的子项目都被迁移为独立项目后,Jakarta名称就不再使用了。所以JCL现在全称是Apache Commons Logging。
SLF4J
全称是Simple Logging Facade For Java,简单日志门面,和JCL功能是类似的,但是JCL一个致命的缺点就是算法复杂,出现问题很难找到原因,而SLF4J的中的Simple就是为了解决这个问题。
Jboss-logging
该组件也是日志门面,但是网上资料很少,使用也并不广泛,直接忽略即可。
| 日志组件 | 全称 | 作用 |
|---|---|---|
| JUL | java.util.logging | sun提供的日志打印工具,没什么人用 |
| Log4J | maven坐标 Log4j:log4j:1.x | apache的一个日志实现,版本是1.x |
| Log4J2 | Log4J的升级版本,2.x版本 | apache对Log4J进行优化的版本 |
| LogBack | LogBack | 一个比log4j优秀的日志实现 |
| JCL | Apache Commons Logging | apache出品的日志接口,不是实现 |
| SLF4J | Simple Logging Facade For Java | 直译就是为java准备的简单的日志门面(门面设计模式) |
| Jboss-logging | jboss出的门面 | 日志门面 |
2.2 门面设计模式
门面设计模式的示例图:
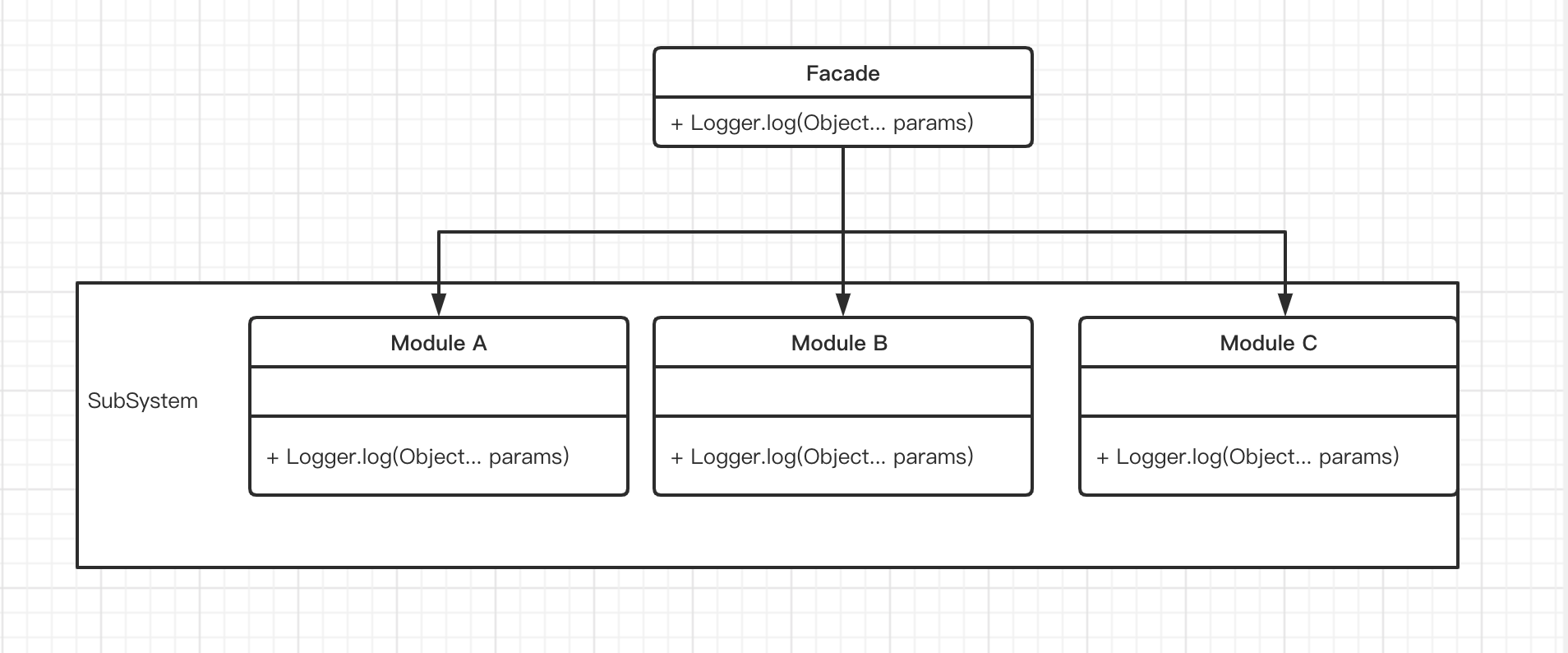
上图中有两种角色:
- 门面(Facade)角色 客户端只与Facade交互,Facade会将请求委派给相应的子系统
- 子系统(SubSystem)角色 具体的功能执行者,可以被客户端调用,也可以被门面调用。
门面设计模式的优点:
- 松散耦合 客户端与具体的子系统并不直接交互,没有耦合关系。
- 简单易用 客户端不需要了解子系统的多个接口使用,只需了解门面提供的接口即可,更换子系统后对客户端毫无影响。
- 更好的划分访问层次 可以按照需要将接口暴露给客户端,对客户端隐藏内部实现细节。
2.3 日志门面具体交互
交互如下图所示:
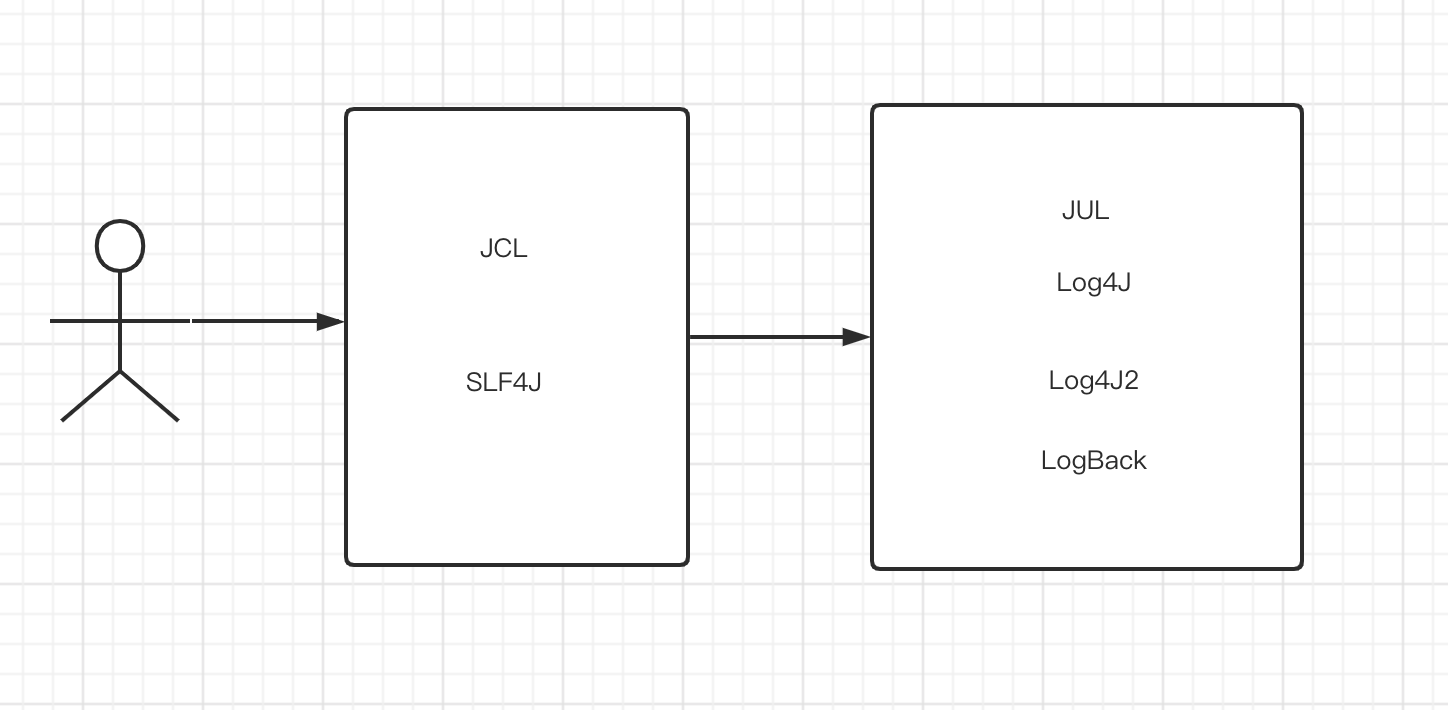
使用日志门面最大的优势就是将系统和具体的日志实现进行解耦。
假如我们直接使用具体的日志框架(比如Log4J),那么系统中的每一处需要打印日志的地方都会耦合Log4J的代码,但假如后面有新的性能更加优异的日志实现,那么切换到新的日志实现的成本是比较大的,需要将每一处日志调用都进行修改。而使用门面日志后,仅仅换下pom依赖即可。
三、Log4J2
3. 1 特性简介
更强的性能
Log4j2的异步模式使用LMAX的diruptor,在多线程环境下的吞吐量是log4j 1.x版本和Logback的18倍之多。可以支持不同的日志门面
比如SLF4J JUL JCL等自动更新配置
可以在运行时重新加载配置,和logback不同的是,重新加载配置时不会丢失日志。高级过滤配置
Log4J2支持基于context data、markers、正则表达式的过滤。插件式
可以支持自定义插件,美团目前的日志组件使用的是自定义的插件。Java 8 Lambda
支持Java 8的lambda表达式,当有些日志组装是比较耗费性能的,可以进行先判断日志级别再进行日志组装。
3.2 基本配置
日志分为以下几个级别:
TRACE < DEBUG < INFO < WARN < ERROR < FATAL<OFF
假如我们设置了一个日志级别,低于这个级别的则不会输出,OFF是关闭日志。
目前常用的有四个:
- DEBUG 一般开发过程中进行联调的日志,生产环境禁止打印debug日志。
- INFO 一般记录一些业务流程日志,在生产环境适量打印。
- WARN 可以用来记录用户输入参数错误的情况,避免用户投诉时无法查到相应日志。
- ERROR 记录系统逻辑出错、调用远程服务出错、各种异常等重要的错误信息。
实际使用时可以酌情采用。
Log4J2的配置结构如下(以xml为例):
Configuration
properties
Appenders
Appender
Layout
Policies
Strategy
Loggers
Logger
RootLogger根节点主要的有两个属性:
- status 用来指定Log4j2内部事件的日志级别,比如需要排查log4j2初始化等内部问题,就可以设置为trace
- monitorInterval 用于监测配置文件变更的时间间隔,单位为秒。
节点说明
Properties
用于定义一些属性,配置文件的其他位置可以使用${}方式进行引用。
Appenders
英文意思为输出源,附着器,即日志的输出位置。可以把Appender理解为管道,管道的一头接着日志,另一头可以对接很多存储位置。比如Console,Flume,JDBC,JMS,JPA,HTTP,Kafka等等,官网上大概是29+种。这里我们就研究使用的较多的RollingRandomAccessFile。
该Appender将日志写入文件中,同时日志文件可以根据TriggeringPolicy和RolloverPolicy进行滚动更新。
- TriggeringPolicy决定日志何时进行滚动,解决的是when的问题。
- RolloverPolicy决定日志怎样滚动,解决的是how的问题。
主要的参数为
fileName
当前日志文件名称,如果这个文件的父目录不存在,则会被创建。
filePattern
这个格式是用于当日志滚动后给旧的日志文件命名的,和上面的fileName一定要区分开。Triggering Policy和Rollover Policy依赖于filePattern。filePattern里可以使用两种格式。
- %d{yyyy-MM-dd HH-mm-ss.SSS} 使用%d指明一个date/time,格式参考Java的SimpleDateFormat。
- %i 表示一个计数值,在Rollover Policy中会用到。
filePattern中可以同时使用%d和%i两种格式,也可以单独使用其中一个。比如
logs/app-%d{yyyy-MM-dd hh}-%ilogs/app-%d{yyyy-MM-dd hh}logs/app-%i都是合法的。name
该appender的名字,在后面loggers中会通过该name引用该appender。
filePermissions
指示创建日志文件时的文件权限,格式为POSIX格式,比如
rw-------rw-rw-rw-Policies
配置具体的Triggering Policy和 Rollover Policy。
关于缓存的相关参数
参数 含义 immediateFlush 设为true,表示每次输出日志都会立即写到磁盘里,默认是True。会对性能有一定的影响。另外,只有当使用的是同步的loggers时,该选项才有效。使用异步logger时会忽略这个选项。 bufferedIO 设为true时,日志会先保存到一个内存缓冲区(除非immediateFlush=true),当缓冲区满了之后才会写到磁盘。性能测试表明使用bufferedIO会有明显的性能提升,即便是设置了immediateFlush=true。默认为true bufferSize 设置了bufferedIO=true时,这个字段表示缓冲区大小,默认是8192bytes patternLayout
其中的属性如下:
- %c 列出logger名字空间的全称,如果加上`{层数}`表示列出从最内层算起的指定层数的命名空间。
假设当前logger名字是a.b.c
| 配置 | 输出 |
| ------- | ------------------------------------------------------------ |
| %c | a.b.c |
| %c{2} | b.c |
| %20c | 若名字空间长度小于20,则左边用空格填充 |
| %-20c | 若名字空间长度小于20,则右边用空格填充 |
| %.20c | 若名字空间长度超过20,则截去多余字符 |
| %20.30c | 若名字空间长度小于20,则左边用空格填充;若名字空间长度超过30,则截去多余字符 |
- %C 列出调用logger的类的全名(包含包路径)
假设当前类是org.spring.boot
| 配置 | 输出 |
| ----- | --------------- |
| %C | org.spring.boot |
| %C{1} | Boot |
- %d 显示日志记录时间 {<日期格式>}
| 配置 | 输出 |
| --------------------------- | ----------------------- |
| %d{yyyy/MM/dd HH:mm:ss,SSS} | 2005/10/12 22:23:30,117 |
| %d{ABSOLUTE} | 22:23:30,117 |
| %d{DEFAULT} | 2021-05-07 18:45:40,840 |
- %F 显示调用logger的原文件名 比如 输出 MyClass.java
- %l 输出日志事件的发生位置,包括类名 线程和在代码中的行数
site.daipeng.truck.server.Slf4JTest.main(Slf4JTest.java:23)
- %L 显示代码行
- %m 显示输出的消息,即调用日志参数
- %M 显示调用logger的方法名称
- %n 当下平台下的换行符
- %p 显示日志级别
- %r 显示从程序启动到记录该条日志经过的毫秒数
- %t 显示具体的线程名
- %x 按NDC(Nested Diagnostic Context,线程堆栈)顺序输出日志
- %X 按MDC(Mapped Diagnostic Context,线程映射表)输出日志。通常用于多个客户端连接同一台服务器,方便服务器区分是那个客户端访问留下来的日志。
- %% 显示一个%Triggering Policy具体类型
Cron Triggering Policy
根据cron表达式来进行日志滚动。内部使用timer进行判断,所以可能会出现应该在下一个日志文件中的日志出现在当前日志的结尾。使用该策略时,需要注意filePattern一定要包含一个date/time,否则日志会被覆盖。
OnStartup Triggering Policy
如果当前日志比jvm启动时间要晚,同时超过了配置的minSize,那么会进行滚动
SizeBased Triggering Policy
日志文件达到了指定的大小则会进行滚动。当和time based triggering策略一起使用时,filePattern一定要包含一个%i的参数,否则目标文件会被覆盖,因为当和time based 一起使用时,Sizebased不会修改日志文件名里的时间。当不和time based策略一起使用时,Sizebased会修改日志文件名里的时间。
<SizeBasedTriggeringPolicy size="20B"/> <SizeBasedTriggeringPolicy size="20MB"/> <SizeBasedTriggeringPolicy size="20GB"/>TimeBased Triggering Policy
根据时间进行日志的滚动。常用参数为两个。
- interval: 间隔多久会产生日志滚动。这个值是一个整形,对应的单位是在filePattern中最小的最具体的那个时间。比如filePattern设置的为%d{yyyy-MM-dd},那么最小的单位就是天;如果为%d{yyyy-MM-dd HH:mm},那么最小的单位就是分钟。
- modulate:指示会不会从0开始进行计算,比如设置为4小时一滚动,当前时间是上午3点,那么上午4点会产生一次日志滚动,下一次是8点,而不是7点。
Composite Triggering Policy
混合策略,可以将上面几种策略混合使用,当符合任何一个策略时都会触发日志滚动。
Rollover Strategies具体类型
Rollover Strategies里最常用的就是DefaultRolloverStrategy,所以这里只介绍这个类型。
如果配置文件中没有显式提供滚动策略,那么也相当于有下面这一行:
<DefaultRolloverStrategy max="7"/> //max默认是7max参数是和filePattern中的%i打配合的,如果filePattern中只有date/time,没有%i计数值,那么max参数不起作用。
- 如果filePattern包含date/time和计数值%i,比如 "logs/app-%d{yyyy-MM-dd HH}-%i",那么每次rollover时,计数器会加1,若达到max值,那么会删除旧的文件。如果当前已经不符合date/time pattern了,那么会更新为当前的date/time,计数器从新从0开始。
- 如果filePattern仅包含计数值%i,那么每次rollover时,文件重命名时计数器将加1,若达到max值,那么会删除旧的文件。
特别注意一点,max参数并不是指保留多少个文件,而是指在同一个date/time下,保留最新的max个文件。
如果filePattern是以".gz", ".zip", ".bz2", ".deflate", ".pack200", ".xz"结尾的,那么旧文件会以filePattern提供的格式进行压缩。这里注意, bzip2, Deflate, Pack200 and XZ 需要 Apache Commons Compress库,XZ还需要 XZ for Java。一般设置为gz基本足够了。
常用参数如下:
| 参数 | 含义 |
|---|---|
| compressionLevel | 压缩级别,0表示不压缩,1表示最快速度,9表示最好压缩质量,只对zip有效。 |
| Min | 计数值%i的最小值 |
| Max | 计数值%i的最大值,默认为7 |
Log4j 2.5 引入了DeleteAction,使用户可以自己控制删除哪些文件,通过这个机制,我们就可以实现更加灵活的日志保存策略。
<DefaultRolloverStrategy max="7">
<Delete basePath="/Users/lvlv/log/" maxDepth="1">
<IfFileName glob="error-*.log.gz" />
<IfLastModified age="100S" />
</Delete>
</DefaultRolloverStrategy>常用参数如下:
- basePath 必填,扫描的目录路径
- maxDepth 扫描的路径深度,为1表示仅扫描basePath下的文件。
- PathConditions: 指的是路径条件,符合的才会被删除。支持复杂的条件嵌套,一般使用的最多的就是下面几个条件:
- IfFileName 判断文件名是否满足正则表达式或者glob表达式,glob是一种简化的正则表达式,glob
- IFLastModified 判断文件的修改时间是否早于指定的duration,参数为age,单位D H M S 表示天 时 分 秒。
- IfAccumulatedFileCount 判断符合条件的文件数量,如果超过了就删除之前的。
<IfAccumulatedFileCount exceeds="10" /> - IfAccumulatedFileSize 判断是否总共的文件大小 单位是B KB MB GB,比如
<IfAccumulatedFileSize exceeds="100 GB" />
假如我们希望每隔5s日志滚动一次,同时日志可以保留50S,那么配置如下:
<RollingFile name="errorLog"
fileName="/Users/lvlv/log/error.log"
filePattern="/Users/lvlv/log/error-%d{yyyy-MM-dd-HH-mm-ss}.log.gz">
<ThresholdFilter level="ERROR" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{DEFAULT} [%t] %l %-5p (%C{1}:%L) - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy interval="5"/>
<!-- <SizeBasedTriggeringPolicy size="20B"/>-->
</Policies>
<DefaultRolloverStrategy max="7">
<Delete basePath="/Users/lvlv/log/" maxDepth="1">
<IfFileName glob="error-*.log.gz" />
<IfLastModified age="50S" />
</Delete>
</DefaultRolloverStrategy>
</RollingFile>Filters
Filter是用于过滤Log Event,Filter可以用于以下四个场景:
- Context-wide 也就是整个xml配置文件级别的
- Logger 级别 用于单个的logger
- Appender 级别 用于单个appender
- Appender Reference 级别 这个是用于判断logger是否需要将Log Event传递给appender
Filter的种类很多,有BurstFilter、CompositeFilter、ThresholdFilter等等,这里主要介绍下ThresholdFilter。
<ThresholdFilter level="TRACE" onMatch="ACCEPT" onMismatch="DENY"/>- Level 表示要匹配的日志级别
- onMatch 如果打印的日志级别大于等于level指定的,那么会返回这个值,可使用ACCEPT DENY NEUTRAL,默认这个值是NEUTRAL
- onMismatch 如果打印的日志级别小于level指定的,那么会返回这个值,可使用ACCEPT DENY NEUTRAL默认是DENY
| 值 | 含义 |
|---|---|
| ACCEPT | 接受 |
| DENY | 拒绝 |
| NEUTRAL | 如果当前不是最后一个过滤器,那么就交给下一个过滤器处理;如果当前是最后一个过滤器,那么就接受。 |
onMatch、onMismatch取值说明:
| 属性 | 含义 |
|---|---|
| onMatch="ACCEPT" | 当日志level>=过滤器level时,接受这条日志。 |
| onMatch="DENY" | 当日志level>=过滤器level时,拒绝这条日志。 |
| onMatch="NEUTRAL" | 当日志level>=过滤器level时,由下一个filter处理,如果当前是最后一个,则接受这条日志。 |
| onMismatch="ACCEPT" | 当日志level<过滤器level时,接受这条日志 |
| onMismatch="DENY" | 当日志level<过滤器level时,拒绝这条日志 |
| onMismatch="NEUTRAL" | 当日志level<过滤器level时,由下一个filter处理,如果当前是最后一个,则接受这条日志 |
举几个例子。
<Filters>
<ThresholdFilter level="ERROR" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
日志大于等于ERROR,那么就接受,否则拒绝。 <Filters>
<ThresholdFilter level="ERROR" onMatch="DENY" onMismatch="NEUTRAL"/>
<ThresholdFilter level="WARN" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
1. 当日志大于等于ERROR时,拒绝日志,当日志小于ERROR时,交由下一个拦截器处理。
2. 当日志大于等于WARN时,接受日志,否则拒绝。
最终结果就是只接受WARN级别日志。Loggers
Loggers节点用来指定哪些日志需要打到哪些appender里。
Loggers有两类子节点,Root节点和Logger节点。
Root
每一个Loggers配置都必须有一个Root节点,Root节点与下面的普通Logger节点区别在于
- Root节点没有name属性
- Root节点不支持additivity属性,因为它没有父级
如果没有配置,那么会使用默认的配置,默认配置级别为ERROR,且将日志输出到ConsoleAppdender中。如下
<Loggers> <Root level="ERROR"> <AppenderRef ref="Console"/> </Root> </Loggers>logger
logger节点的属性如下:
name
首先说下代码中logger的name。获取Logger有两种方式。
第一种:
private static Logger logger = LoggerFactory.getLogger(Slf4JTest.class);这种方式会使用Slf4jTest.class.getName()的值作为logger的name。
第二种:
private static Logger logger = LoggerFactory.getLogger("site.daipeng.truck.slf4jTest");这种方式会直接使用
"site.daipeng.truck.slf4jTest"作为logger的name。而logger节点中的name和代码中Logger对象的name是有关联关系的。举个例子。
logger节点中的name Logger对象中的name 是否可以匹配 site.daipeng.truck site.daipeng.truck.test 匹配 site.daipeng.truck site.daipeng.truck.slf4jTest 匹配 site.daipeng.truck site.daipeng 不匹配 可以看到,logger节点中的name实际是指定了一个范围,这个范围圈定的规则是和java的package一致的,存在父子继承关系。
实际上Logger对象的name可以随意设置,只要你不嫌配置logger节点麻烦就行。
实际的应用中,获取Logger我们会采用上面的第一种类参数的方式,从而隐含了一个package的概念,在logger节点配置时就会直接配置成相应的package名。
level
即日志的等级。只有大于等于设置的等级才可以输出到appender中。
additivity
是否叠加输出。默认为true。设置为false表示就在本logger配置的appender内输出即可,不需要在父级appender输出了。这个原理类似于javascript里的冒泡原理,即事件是否会一直冒泡到最顶级的dom元素。
举几个例子,假如代码中的Logger对象的名字是
site.daipeng.truck.server.slf4jTest。<Loggers> <Root level="error"> <AppenderRef ref="Console"/> </Root> <logger name="site.daipeng.truck.server" level="ERROR" additivity="true"> <AppenderRef ref="Console"></AppenderRef> </logger> <logger name="site.daipeng.truck" level="ERROR" additivity="true"> <AppenderRef ref="errorLog"></AppenderRef> </logger> </Loggers> 日志首先会输出到"site.daipeng.truck.server"中,然后发现additivity="true",那么就会继续往上冒泡,继续输出到"site.daipeng.truck",而这个logger节点的additivity也是true,那么就会继续的冒泡,直到最后的Root logger。 日志最后会出现在errorLog Appender中,同时会在Console Appender中输出两遍(一个父节点logger和一个Root logger)<Loggers> <Root level="error"> <AppenderRef ref="Console"/> </Root> <logger name="site.daipeng.truck.server" level="ERROR" additivity="true"> <AppenderRef ref="Console"></AppenderRef> </logger> <logger name="site.daipeng.truck" level="ERROR" additivity="false"> <AppenderRef ref="errorLog"></AppenderRef> </logger> </Loggers> 日志首先会输出到"site.daipeng.truck.server"中,然后发现additivity="true",那么就会继续往上冒泡,继续输出到"site.daipeng.truck",而这个logger节点的additivity是false,那么就会停止冒泡。 日志最后会出现在errorLog Appender中,同时会在Console Appender中输出一遍(一个父节点logger)AppenderRef
这个节点是用于指明日志需要输出到哪些appender中的,可以配置多个appender,会依次输出。logger会继承Root的AppenderRef。
Logger配置了AppenderRef Logger没有配置了AppenderRef logger配置了additivity="true" 日志首先输出到logger内的Appender,然后再输出到Root下的Appender 日志输出到Root内的Appender logger配置了additivity="false" 日志首先输出到logger内的Appender,但不再输出到Root下的Appender 日志将无处可去,不会输出。
3.3 高性能异步模式
Log4J2的异步模式分为两种,一种是AsyncAppender模式,一种是AsyncLogger模式。
AsyncAppender
AsyncAppender的异步实现是通过将LogEvent放到ArrayBlockingQueue里,通过另一个线程将LogEvent写入到具体的Appender中。
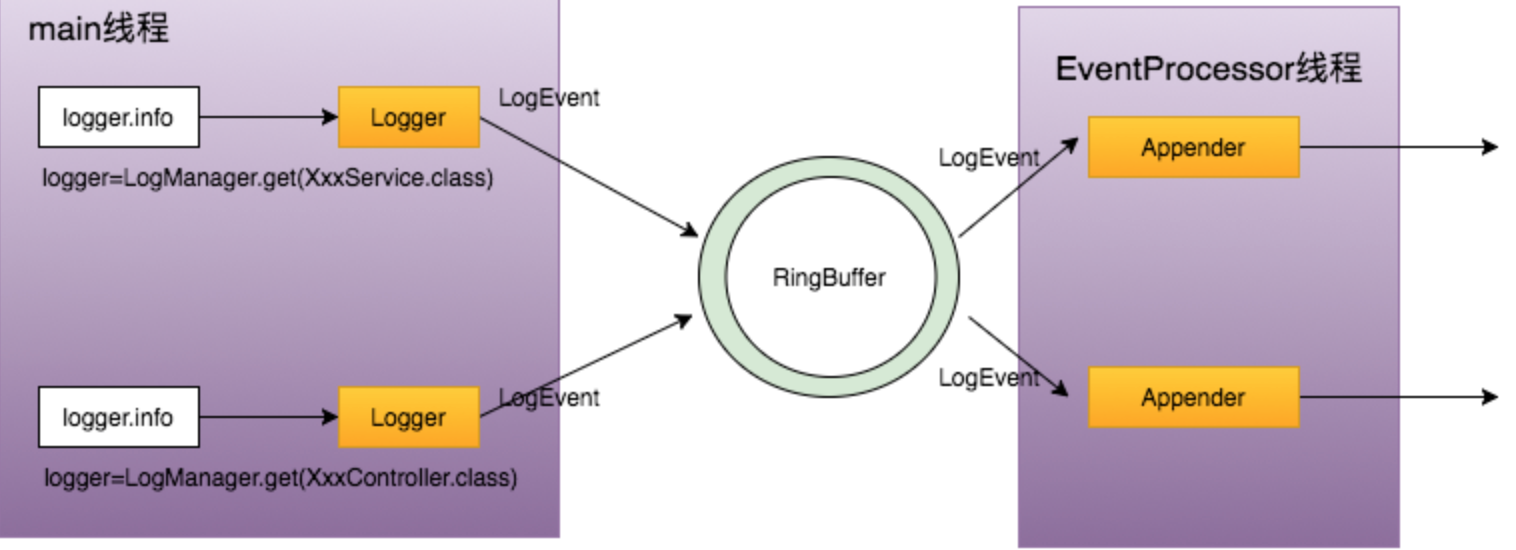
主要参数如下:
参数名 类型 说明 name String Async Appender的名字 AppenderRef String 实际使用的appender,可以配置多个 blocking boolean 默认为true。当queue满了后,如果该值为true,appender会等待queue直到有空余位置;如果为false,则LogEvent会传递给error appender进行处理。 bufferSize integer 指定queue的大小,默认是128。如果使用的是disruptor类型的BlockingQueue,这个值需要设置为2的幂。假如应用打印日志的速度快于appender输出的速度,那么当queue满了之后,会根据AsyncQueueFullPolicy进行处理。 includeLocation boolean 解析日志打印时的具体位置信息是一个非常昂贵的操作,一般的会使打印速度降低5-20倍,默认是false。 如下使用AsyncAppender的例子:
<?xml version="1.0" encoding="UTF-8"?> <Configuration status="warn" name="MyApp" packages=""> <Appenders> <File name="MyFile" fileName="logs/app.log"> <PatternLayout> <Pattern>%d %p %c{1.} [%t] %m%n</Pattern> </PatternLayout> </File> <Async name="Async"> <AppenderRef ref="MyFile"/> </Async> </Appenders> <Loggers> <Root level="error"> <AppenderRef ref="Async"/> </Root> </Loggers> </Configuration>
从Log4J 2.7后,可以使用如下几种Queue:
| 名称 | 含义 |
|---|---|
| ArrayBlockingQueue | 默认的Queue,具体实现即Java提供的ArrayBlockingQueue |
| DisruptorBlockingQueue | 使用Blocking Queue的Conversant Disruptor实现 |
| JCToolsBlockingQueue | 使用JCTools |
| LinkedTransferQueue | 使用Java 7提供的LinkedTransferQueue,注意这个Queue不使用bufferSize参数,因为LinkedTransferQueue不支持最大容量。 |
AsyncLogger
AsyncLogger使用了一个高性能的无锁的线程通信框架-Disruptor,有关这个框架的介绍可以参考高性能队列。
img 优点如下:
- 更高的吞吐量,比同步的logger有6-68倍的提升。
- 因为是异步执行,日志调用代码会立即返回,所以延迟非常低。
缺点如下:
- 错误处理。因为是异步处理,异常很难通知到应用程序,虽然可以通过ExceptionHandler来解决一部分问题,但是无法覆盖全部的情形。所以如果日志对你很重要,比如是应用逻辑的一部分或者是审计日志,那么最好使用同步日志。
- 对于可变的日志消息一定要注意,虽然大多数的消息处理时会使用参数的快照,但是对于MapMessage和StructureDataMessage来说(这两者本来就是为了可变而设计的),随时可能会修改某些属性,导致这些修改可能会在日志中被看到也可能不会。
- 假如你的服务器配置比较低,比如只有一个CPU核,那么同步日志和异步日志性能差不多。
AsyncLogger使用时有两种方式。下面两种方式都依赖disruptor,Log4j-2.9+的版本依赖于disruptor-3.3.4+,Log4j-2.9之前的版本依赖disruptor-3.0.0+。
3.1.1 仅使用异步Logger
这种配置是最简单的同时也是性能最好的,只需要添加disruptor到classpath,同时设置system property中的og4j2.contextSelector为org.apache.logging.log4j.core.async.AsyncLoggerContextSelector即可。
默认情形下,includeLocation是false,如果你的日志输出pattern使用了location信息,那么需要修改这个配置为true。
代码示例如下:
<?xml version="1.0" encoding="UTF-8"?> <!-- Don't forget to set system property 需要加上这个system property -Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector to make all loggers asynchronous. --> <Configuration status="WARN"> <Appenders> <!-- 关闭immediateFlush --> <!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. --> <RandomAccessFile name="RandomAccessFile" fileName="async.log" immediateFlush="false" append="false"> <PatternLayout> <Pattern>%d %p %c{1.} [%t] %m %ex%n</Pattern> </PatternLayout> </RandomAccessFile> </Appenders> <Loggers> <Root level="info" includeLocation="false"> <AppenderRef ref="RandomAccessFile"/> </Root> </Loggers> </Configuration>需要注意的是,指定了system property为异步日志后,全局都是异步的,所以在配置文件中依然要使用正常的root和logger。
3.2.1混合使用同步和异步Logger
我们可以混合使用同步和异步Logger,这样会带来更大的灵活性。
配置示例如下:
<?xml version="1.0" encoding="UTF-8"?> <!-- No need to set system property "log4j2.contextSelector" to any value when using <asyncLogger> or <asyncRoot>. --> <Configuration status="WARN"> <Appenders> <!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. --> <RandomAccessFile name="RandomAccessFile" fileName="asyncWithLocation.log" immediateFlush="false" append="false"> <PatternLayout> <Pattern>%d %p %class{1.} [%t] %location %m %ex%n</Pattern> </PatternLayout> </RandomAccessFile> </Appenders> <Loggers> <!-- pattern layout actually uses location, so we need to include it --> <!-- 使用异步logger --> <AsyncLogger name="com.foo.Bar" level="trace" includeLocation="true"> <AppenderRef ref="RandomAccessFile"/> </AsyncLogger> <Root level="info" includeLocation="true"> <AppenderRef ref="RandomAccessFile"/> </Root> </Loggers> </Configuration>关于includeLocation与Pattern的关系,如果pattern中使用了
%C or $class, %F or %file, %l or %location, %L or %line, %M or %method,这些格式,那么就需要设置includeLocation="true"。也可以使用AsyncRoot配置根Logger。
<AsyncRoot level="INFO" includeLocation="true"> <AppenderRef ref="errorLog"/> </AsyncRoot>实际性能测试
官网给了几组测试数据,性能是非常优异。图片找不到了,但结论是肯定的。
3.4 运行时修改日志配置
Log4j2的配置文件中有一个monitorInterval属性,表示监测配置文件变更的时间间隔,当我们修改log4j2.xml配置文件后,经过这个时间间隔后,会自动的重新加载新的配置,通过这个机制,可以实现在运行时动态的修改日志配置而不用重新修改代码部署服务。注意在IDE中进行测试时,要修改target/目录下的配置文件。
3.5 日志配置文件示例
3.5.1 SLF4J整合其他日志实现
这里引用官网的一张图例:
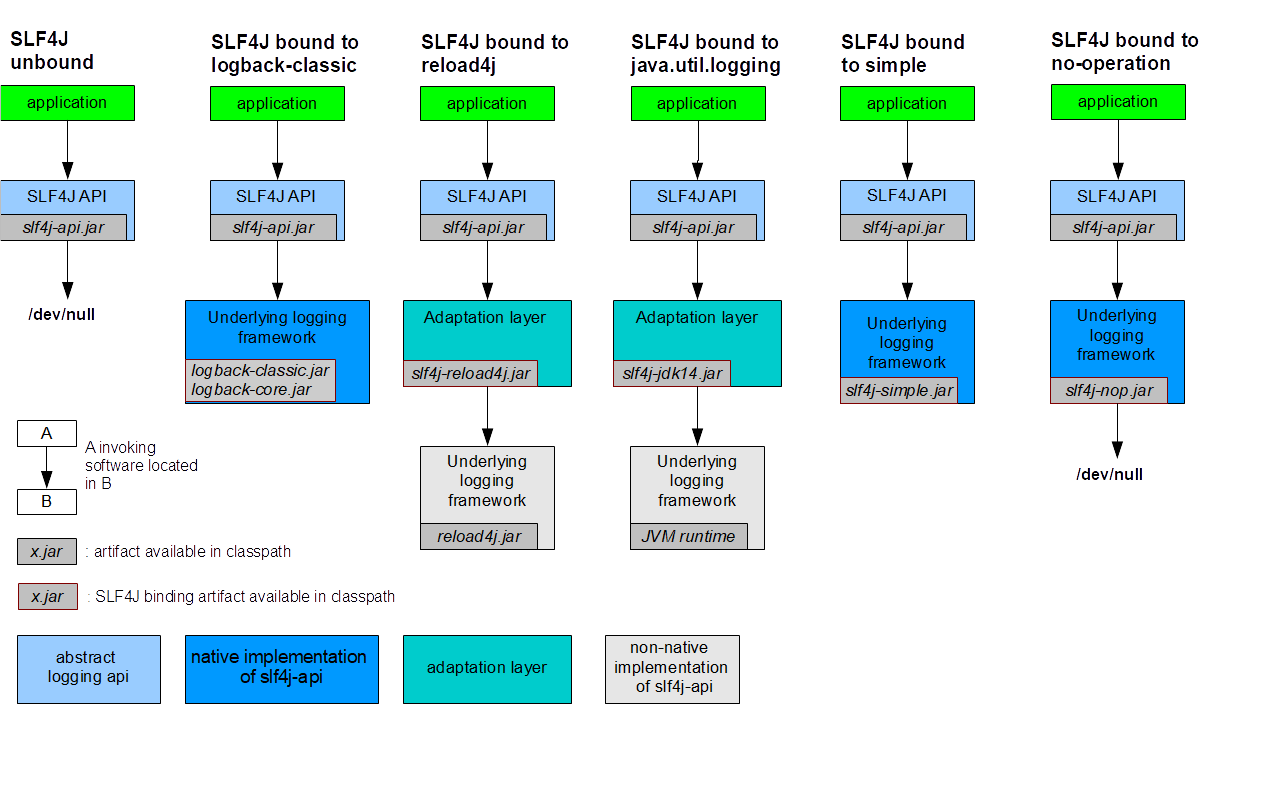
这张图里基本上把slf4j与其他日志实现集成安排的明明白白了。不过这里面没有提到SLF4J与Log4J2的集成,我们来补上。
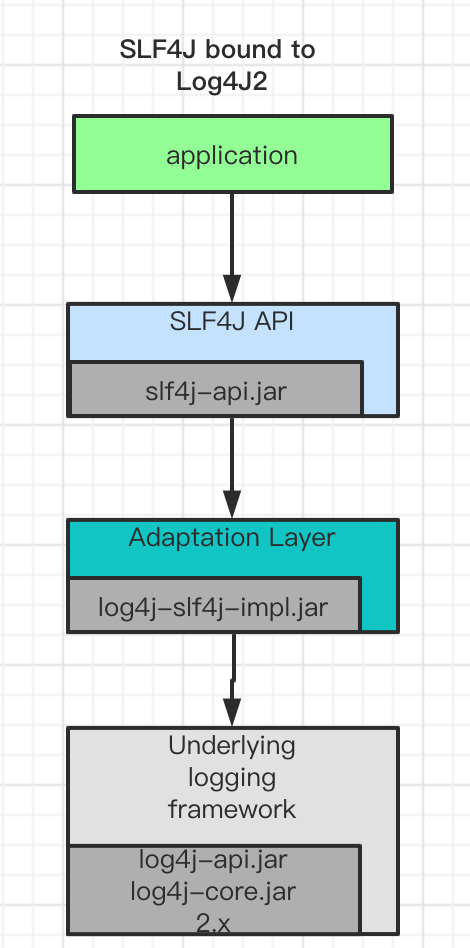
当系统采用Log4J2作为日志框架实现时,执行步骤如下:
- 首先系统使用slf4j-api提供的方法进行日志打印。
- 编译时slf4j-api会查找具体的日志实现
- Log4j-slf4j-implui是桥接类,可以让slf4j获取实际的日志输出实例。
- Log4j-core Log4j-api这两个是实际的日志实现。
3.5.2 springboot Log4j2使用
springboot整合Slf4j Log4j2很简单,首先配置pom依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<!-- 排除掉自带的 -->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>在springboot配置文件中增加
logging:
config: classpath:log4j2/log4j2.test.xml //具体的配置文件路径3.5.3 源码解析
我们按照调用一步一步看下是如何获取到Logger对象的。
//调用getLogger方法
private static Logger logger = LoggerFactory.getLogger(Slf4JTest.class);
public static Logger getLogger(Class<?> clazz) {
//实际调用
Logger logger = getLogger(clazz.getName());
... 省略
return logger;
}
//实际上是先获取ILoggerFactory,一看就是工厂模式
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
//返回真正的Logger
return iLoggerFactory.getLogger(name);
}
public static ILoggerFactory getILoggerFactory() {
if (INITIALIZATION_STATE == 0) {
INITIALIZATION_STATE = 1;
//执行初始化,关键在这里
performInitialization();
}
switch(INITIALIZATION_STATE) {
case 1:
return TEMP_FACTORY;
case 2:
throw new IllegalStateException("org.slf4j.LoggerFactory could not be successfully initialized. See also http://www.slf4j.org/codes.html#unsuccessfulInit");
case 3:
//返回真正的LoggerFactory
return StaticLoggerBinder.getSingleton().getLoggerFactory();
case 4:
return NOP_FALLBACK_FACTORY;
default:
throw new IllegalStateException("Unreachable code");
}
}
private static final void performInitialization() {
//关键是在bind方法里
bind();
if (INITIALIZATION_STATE == 3) {
versionSanityCheck();
}
}
// bind是实际的处理逻辑
private static final void bind() {
String msg;
try {
//查找实际的StaticLoggerBinder
Set<URL> staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();
//假如有多个StaticLoggerBinder,那么就进行提示
reportMultipleBindingAmbiguity(staticLoggerBinderPathSet);
//假如多个,那么jvm给哪个,就用哪个,这个实际是用于判断下到底有没有staticLoggerBinder,如果没有就直接抛异常了。
StaticLoggerBinder.getSingleton();
INITIALIZATION_STATE = 3;
//上报到底是使用了哪一个StaticLoggerBinder
reportActualBinding(staticLoggerBinderPathSet);
fixSubstitutedLoggers();
} catch (NoClassDefFoundError var2) {
msg = var2.getMessage();
if (!messageContainsOrgSlf4jImplStaticLoggerBinder(msg)) {
failedBinding(var2);
throw var2;
}
INITIALIZATION_STATE = 4;
Util.report("Failed to load class \"org.slf4j.impl.StaticLoggerBinder\".");
Util.report("Defaulting to no-operation (NOP) logger implementation");
Util.report("See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.");
} catch (NoSuchMethodError var3) {
msg = var3.getMessage();
if (msg != null && msg.indexOf("org.slf4j.impl.StaticLoggerBinder.getSingleton()") != -1) {
INITIALIZATION_STATE = 2;
Util.report("slf4j-api 1.6.x (or later) is incompatible with this binding.");
Util.report("Your binding is version 1.5.5 or earlier.");
Util.report("Upgrade your binding to version 1.6.x.");
}
throw var3;
} catch (Exception var4) {
failedBinding(var4);
throw new IllegalStateException("Unexpected initialization failure", var4);
}
}看源码后,我们会发现StaticLoggerBinder是比较重要的,我们来找一下log4j-slf4j-impl桥接器中的StaticLoggerBinder。
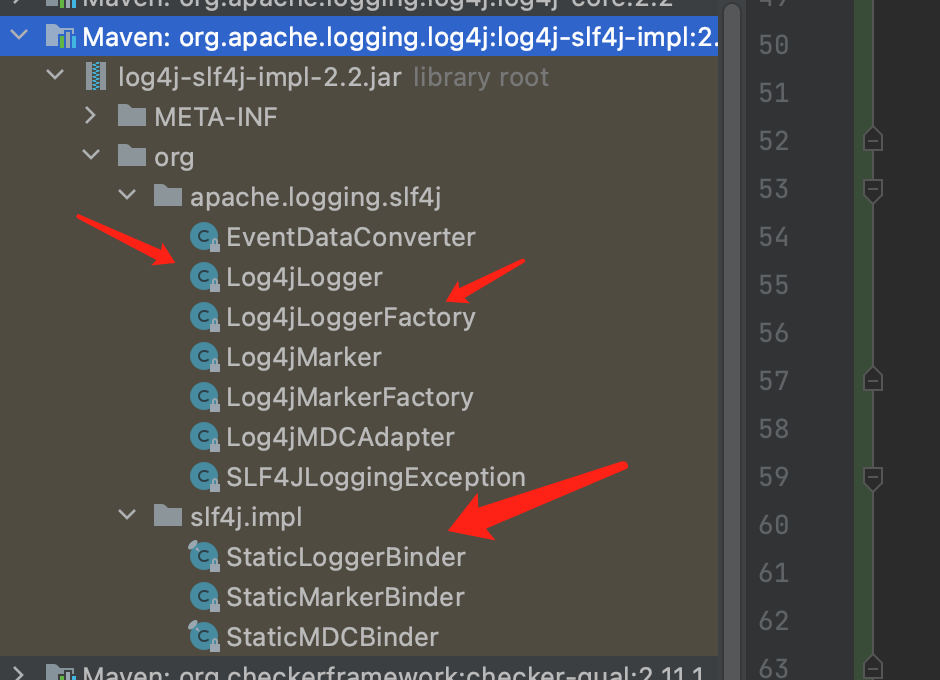
可以看到,桥接器里有两个包名,一个是org.apache.logging.slf4j,一个是org.slf4j.impl,也就是桥接器里的org.slf4j.impl.StaticLoggerBinder是实际使用的,这个类代码如下:
package org.slf4j.spi;
import org.slf4j.ILoggerFactory;
//slf4j定义的接口
public interface LoggerFactoryBinder {
ILoggerFactory getLoggerFactory();
String getLoggerFactoryClassStr();
}
//实现slf4j定义的接口
public final class StaticLoggerBinder implements LoggerFactoryBinder {
public static String REQUESTED_API_VERSION = "1.6";
private static final String LOGGER_FACTORY_CLASS_STR = Log4jLoggerFactory.class.getName();
private static final StaticLoggerBinder SINGLETON = new StaticLoggerBinder();
//实际的LoggerFactory是Log4jLoggerFactory。
private final ILoggerFactory loggerFactory = new Log4jLoggerFactory();
private StaticLoggerBinder() {
}
public static StaticLoggerBinder getSingleton() {
return SINGLETON;
}
public ILoggerFactory getLoggerFactory() {
return this.loggerFactory;
}
public String getLoggerFactoryClassStr() {
return LOGGER_FACTORY_CLASS_STR;
}
}这下就真相大白了。
基本流程如下:
- 查找并加载所有的org.slf4j.impl.StaticLoggerBinder。
- 如果StaticLoggerBinder个数大于1个,那么使用jvm依据一定的规则提供的一个。
- 如果StaticLoggerBinder个数为0,那么直接报错,输出日志提示没有可用的日志实现。
- 调用StaticLoggerBinder的getLoggerFactory方法拿到具体的ILoggerFactory。
- 调用ILoggerFactory的getLogger方法拿到最终的Logger对象。
强制使用Log4j2日志 System.setProperty("org.springframework.boot.logging.LoggingSystem","org.springframework.boot.logging.log4j2.Log4J2LoggingSystem");四、 关键的步骤
上面的配置文件log4j2.xml请访问公众号查询下载链接。

在公众号中发送日志配置文件 即可。